На мой взгляд, как студента, эконометрика – это одна из самых прикладных наук из всех, с которыми мне удалось познакомиться в стенах своего университета. С помощью неё, действительно, можно решать задачи прикладного характера в масштабах предприятия. Насколько эффективными будут эти решения – вопрос третий. Суть в том, что большая часть знаний так и останется теорией, а вот эконометрика и регрессионный анализ всё-таки стоит изучить с особым вниманием.
Что объясняет регрессия?
Прежде, чем мы приступим к рассмотрению функций MS Excel, позволяющих, решать данные задачи, хотелось бы вам на пальцах объяснить, что, в сущности, предполагает регрессионный анализ. Так вам проще будет сдавать экзамен, а самое главное, интересней изучать предмет.
Будем надеяться, вы знакомы с понятием функции из математики. Функция – это взаимосвязь двух переменных. При изменении одной переменной что-то происходит с другой. Изменяем X, меняется и Y, соответственно. Функциями описываются различные законы. Зная функцию, мы можем подставлять произвольные значения X и смотреть на то, как при этом изменится Y.
Это имеет большое значение, поскольку регрессия – это попытка объяснить с помощью определённой функции на первый взгляд бессистемные и хаотичные процессы. Так, например, можно выявить взаимосвязь курса доллара и безработицы в России.
Если данную закономерность обнаружить удастся, то по полученной нами в ходе расчетов функции, мы сможем составить прогноз, какой будет уровень безработицы при N-ом курсе доллара по отношению к рублю.
Данная взаимосвязь будет называться корреляцией. Регрессионный анализ предполагает расчет коэффициента корреляции, который объяснит тесноту связи между рассматриваемыми нами переменными (курсом доллара и числом рабочих мест).
Данный коэффициент может быть положительным и отрицательным. Его значения находятся в пределах от -1 до 1. Соответственно, мы может наблюдать высокую отрицательную или положительную корреляцию. Если она положительная, то за увеличением курса доллара последует и появление новых рабочих мест. Если она отрицательная, значит, за увеличением курса, последует уменьшение рабочих мест.
Регрессия бывает нескольких видов. Она может быть линейной, параболической, степенной, экспоненциальной и т.д. Выбор модели мы делаем в зависимости от того, какая регрессия будет соответствовать конкретно нашему случаю, какая модель будет максимально близка к нашей корреляции. Рассмотрим это на примере задачи и решим её в MS Excel.
Линейная регрессия в MS Excel
Для решения задач линейной регрессии вам понадобится функционал «Анализ данных». Он может быть не включен у вас поэтому его нужно активировать.
- Жмём на кнопку «Файл»;
- Выбираем пункт «Параметры»;
- Жмём по предпоследней вкладке «Надстройки» с левой стороны;

- Снизу увидим Надпись «Управление» и кнопку «Перейти». Жмём по ней;
- Ставим галочку на «Пакет анализа»;
- Жмём «ок».

Пример задачи
Функция пакетного анализа активирована. Решим следующую задачу. У нас есть выборка данных за несколько лет о числе ЧП на территории предприятия и количестве трудоустроенных работников. Нам необходимо выявить взаимосвязь между этими двумя переменными. Есть объясняющая переменная X – это число рабочих и объясняемая переменная – Y – это число чрезвычайных происшествий. Распределим исходные данные в два столбца.
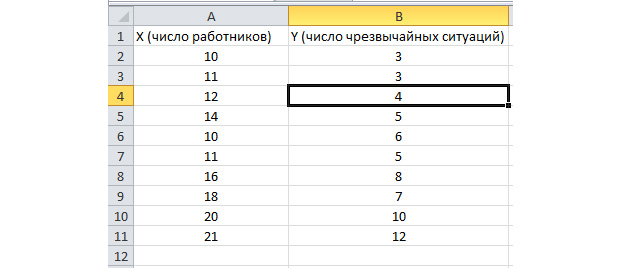
Перейдём во вкладку «данные» и выберем «Анализ данных»
В появившемся списке выбираем «Регрессия». Во входных интервалах Y и X выбираем соответствующие значения.

Нажимаем «Ок». Анализ произведён, и в новом листе мы увидим результаты.
Наиболее существенные для нас значения отмечены на рисунке ниже.

Множественный R – это коэффициент детерминации. Он имеет сложную формулу расчета и показывает, насколько можно доверять нашему коэффициенту корреляции. Соответственно, чем больше это значение, тем больше доверия, тем удачнее наша модель в целом.
Y-пересечение и Пересечение X1 – это коэффициенты нашей регрессии. Как уже было сказано, регрессия – это функция, и у неё есть определённые коэффициенты. Таким образом, наша функция будет иметь вид: Y = 0,64*X-2,84.
Что нам это даёт? Это даёт нам возможность составить прогноз. Допустим, мы хотим нанять на предприятие 25 работников и нам нужно примерно представить, каким при этом будет количество чрезвычайных происшествий. Подставляем в нашу функцию данное значение и получаем результат Y = 0,64 * 25 – 2,84. Примерно 13 ЧП у нас будет происходить.
Посмотрим, как это работает. Взгляните на рисунок ниже. В полученную нами функцию подставлены фактические значения по вовлеченным работникам. Посмотрите, как близки значения к реальным игрекам.

Вы так же можете построить поле корреляции, выделив область игреков и иксов, нажав на вкладку «вставку» и выбрав точечную диаграмму.

Точки идут вразброс, но в целом двигаются вверх, как будто посередине лежит прямая линия. И эту линию вы так же можете добавить, перейдя во вкладку «Макет» в MS Excel и выбрав пункт «Линия тренда»
Щелкните дважды по появившейся линии и увидите то, о чем говорилось ранее. Вы можете изменять тип регрессии в зависимости от того, как выглядит ваше поле корреляции.
Возможно, вам покажется, что точки рисуют параболу, а не прямую линию и вам целесообразней выбрать другой тип регрессии.

Заключение
Будем надеяться, что данная статья дала вам большее понимание о том, что такое регрессионный анализ и для чего он нужен. Всё это имеет большое прикладное значение.
Регрессионный анализ — это статистический метод исследования, позволяющий показать зависимость того или иного параметра от одной либо нескольких независимых переменных. В докомпьютерную эру его применение было достаточно затруднительно, особенно если речь шла о больших объемах данных. Сегодня, узнав как построить регрессию в Excel, можно решать сложные статистические задачи буквально за пару минут. Ниже представлены конкретные примеры из области экономики.
Виды регрессии
Само это понятие было введено в математику в 1886 году. Регрессия бывает:
- линейной;
- параболической;
- степенной;
- экспоненциальной;
- гиперболической;
- показательной;
- логарифмической.
Пример 1
Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях.
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Количество уволившихся | Зарплата |
||
30000 рублей |
|||
35000 рублей |
|||
40000 рублей |
|||
45000 рублей |
|||
50000 рублей |
|||
55000 рублей |
|||
60000 рублей |
Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а 0 + а 1 x 1 +…+а k x k , где х i — влияющие переменные, a i — коэффициенты регрессии, a k — число факторов.
Для данной задачи Y — это показатель уволившихся сотрудников, а влияющий фактор — зарплата, которую обозначаем X.
Использование возможностей табличного процессора «Эксель»
Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно:
- с вкладки «Файл» перейти в раздел «Параметры»;
- в открывшемся окне выбрать строку «Надстройки»;
- щелкнуть по кнопке «Перейти», расположенной внизу, справа от строки «Управление»;
- поставить галочку рядом с названием «Пакет анализа» и подтвердить свои действия, нажав «Ок».
Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка.
в Excel
Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого:
- щелкаем по кнопке «Анализ данных»;
- в открывшемся окне нажимаем на кнопку «Регрессия»;
- в появившуюся вкладку вводим диапазон значений для Y (количество уволившихся работников) и для X (их зарплаты);
- подтверждаем свои действия нажатием кнопки «Ok».
В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии. Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных.
Анализ результатов регрессии для R-квадрата
В Excel данные полученные в ходе обработки данных рассматриваемого примера имеют вид:
Прежде всего, следует обратить внимание на значение R-квадрата. Он представляет собой коэффициент детерминации. В данном примере R-квадрат = 0,755 (75,5%), т. е. расчетные параметры модели объясняют зависимость между рассматриваемыми параметрами на 75,5 %. Чем выше значение коэффициента детерминации, тем выбранная модель считается более применимой для конкретной задачи. Считается, что она корректно описывает реальную ситуацию при значении R-квадрата выше 0,8. Если R-квадрата<0,5, то такой анализа регрессии в Excel нельзя считать резонным.
Анализ коэффициентов
Число 64,1428 показывает, каким будет значение Y, если все переменные xi в рассматриваемой нами модели обнулятся. Иными словами можно утверждать, что на значение анализируемого параметра оказывают влияние и другие факторы, не описанные в конкретной модели.
Следующий коэффициент -0,16285, расположенный в ячейке B18, показывает весомость влияния переменной Х на Y. Это значит, что среднемесячная зарплата сотрудников в пределах рассматриваемой модели влияет на число уволившихся с весом -0,16285, т. е. степень ее влияния совсем небольшая. Знак «-» указывает на то, что коэффициент имеет отрицательное значение. Это очевидно, так как всем известно, что чем больше зарплата на предприятии, тем меньше людей выражают желание расторгнуть трудовой договор или увольняется.
Множественная регрессия
Под таким термином понимается уравнение связи с несколькими независимыми переменными вида:
y=f(x 1 +x 2 +…x m) + ε, где y — это результативный признак (зависимая переменная), а x 1 , x 2 , …x m — это признаки-факторы (независимые переменные).
Оценка параметров
Для множественной регрессии (МР) ее осуществляют, используя метод наименьших квадратов (МНК). Для линейных уравнений вида Y = a + b 1 x 1 +…+b m x m + ε строим систему нормальных уравнений (см. ниже)

Чтобы понять принцип метода, рассмотрим двухфакторный случай. Тогда имеем ситуацию, описываемую формулой

Отсюда получаем:

где σ — это дисперсия соответствующего признака, отраженного в индексе.
МНК применим к уравнению МР в стандартизируемом масштабе. В таком случае получаем уравнение:

в котором t y , t x 1, … t xm — стандартизируемые переменные, для которых средние значения равны 0; β i — стандартизированные коэффициенты регрессии, а среднеквадратическое отклонение — 1.
Обратите внимание, что все β i в данном случае заданы, как нормируемые и централизируемые, поэтому их сравнение между собой считается корректным и допустимым. Кроме того, принято осуществлять отсев факторов, отбрасывая те из них, у которых наименьшие значения βi.
Задача с использованием уравнения линейной регрессии
Предположим, имеется таблица динамики цены конкретного товара N в течение последних 8 месяцев. Необходимо принять решение о целесообразности приобретения его партии по цене 1850 руб./т.
номер месяца | название месяца | цена товара N |
|
1750 рублей за тонну |
|||
1755 рублей за тонну |
|||
1767 рублей за тонну |
|||
1760 рублей за тонну |
|||
1770 рублей за тонну |
|||
1790 рублей за тонну |
|||
1810 рублей за тонну |
|||
1840 рублей за тонну |
|||
Для решения этой задачи в табличном процессоре «Эксель» требуется задействовать уже известный по представленному выше примеру инструмент «Анализ данных». Далее выбирают раздел «Регрессия» и задают параметры. Нужно помнить, что в поле «Входной интервал Y» должен вводиться диапазон значений для зависимой переменной (в данном случае цены на товар в конкретные месяцы года), а в «Входной интервал X» — для независимой (номер месяца). Подтверждаем действия нажатием «Ok». На новом листе (если так было указано) получаем данные для регрессии.
Строим по ним линейное уравнение вида y=ax+b, где в качестве параметров a и b выступают коэффициенты строки с наименованием номера месяца и коэффициенты и строки «Y-пересечение» из листа с результатами регрессионного анализа. Таким образом, линейное уравнение регрессии (УР) для задачи 3 записывается в виде:
Цена на товар N = 11,714* номер месяца + 1727,54.
или в алгебраических обозначениях
y = 11,714 x + 1727,54
Анализ результатов
Чтобы решить, адекватно ли полученное уравнения линейной регрессии, используются коэффициенты множественной корреляции (КМК) и детерминации, а также критерий Фишера и критерий Стьюдента. В таблице «Эксель» с результатами регрессии они выступают под названиями множественный R, R-квадрат, F-статистика и t-статистика соответственно.
КМК R дает возможность оценить тесноту вероятностной связи между независимой и зависимой переменными. Ее высокое значение свидетельствует о достаточно сильной связи между переменными «Номер месяца» и «Цена товара N в рублях за 1 тонну». Однако, характер этой связи остается неизвестным.
Квадрат коэффициента детерминации R 2 (RI) представляет собой числовую характеристику доли общего разброса и показывает, разброс какой части экспериментальных данных, т.е. значений зависимой переменной соответствует уравнению линейной регрессии. В рассматриваемой задаче эта величина равна 84,8%, т. е. статистические данные с высокой степенью точности описываются полученным УР.
F-статистика, называемая также критерием Фишера, используется для оценки значимости линейной зависимости, опровергая или подтверждая гипотезу о ее существовании.
(критерий Стьюдента) помогает оценивать значимость коэффициента при неизвестной либо свободного члена линейной зависимости. Если значение t-критерия > t кр, то гипотеза о незначимости свободного члена линейного уравнения отвергается.
В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%.
Таким образом, можно утверждать, что полученное уравнение линейной регрессии адекватно.
Задача о целесообразности покупки пакета акций
Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу.
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
- кредиторская задолженность (VK);
- объем годового оборота (VO);
- дебиторская задолженность (VD);
- стоимость основных фондов (СОФ).
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Решение средствами табличного процессора Excel
Прежде всего, необходимо составить таблицу исходных данных. Она имеет следующий вид:

- вызывают окно «Анализ данных»;
- выбирают раздел «Регрессия»;
- в окошко «Входной интервал Y» вводят диапазон значений зависимых переменных из столбца G;
- щелкают по иконке с красной стрелкой справа от окна «Входной интервал X» и выделяют на листе диапазон всех значений из столбцов B,C, D, F.
Отмечают пункт «Новый рабочий лист» и нажимают «Ok».
Получают анализ регрессии для данной задачи.

Изучение результатов и выводы
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
СП = 0,103*СОФ + 0,541*VO - 0,031*VK +0,405*VD +0,691*VZP - 265,844.
В более привычном математическом виде его можно записать, как:
y = 0,103*x1 + 0,541*x2 - 0,031*x3 +0,405*x4 +0,691*x5 - 265,844
Данные для АО «MMM» представлены в таблице:
Подставив их в уравнение регрессии, получают цифру в 64,72 млн американских долларов. Это значит, что акции АО «MMM» не стоит приобретать, так как их стоимость в 70 млн американских долларов достаточно завышена.
Как видим, использование табличного процессора «Эксель» и уравнения регрессии позволило принять обоснованное решение относительно целесообразности вполне конкретной сделки.
Теперь вы знаете, что такое регрессия. Примеры в Excel, рассмотренные выше, помогут вам в решение практических задач из области эконометрики.
В предыдущих заметках предметом анализа часто становилась отдельная числовая переменная, например, доходность взаимных фондов, время загрузки Web-страницы или объем потребления безалкогольных напитков. В настоящей и следующих заметках мы рассмотрим методы предсказания значений числовой переменной в зависимости от значений одной или нескольких других числовых переменных.
Материал будет проиллюстрирован сквозным примером. Прогнозирование объема продаж в магазине одежды. Сеть магазинов уцененной одежды Sunflowers на протяжении 25 лет постоянно расширялась. Однако в настоящее время у компании нет систематического подхода к выбору новых торговых точек. Место, в котором компания собирается открыть новый магазин, определяется на основе субъективных соображений. Критериями выбора являются выгодные условия аренды или представления менеджера об идеальном местоположении магазина. Представьте, что вы - руководитель отдела специальных проектов и планирования. Вам поручили разработать стратегический план открытия новых магазинов. Этот план должен содержать прогноз годового объема продаж во вновь открываемых магазинах. Вы полагаете, что торговая площадь непосредственно связана с объемом выручки, и хотите учесть этот факт в процессе принятия решения. Как разработать статистическую модель, позволяющую прогнозировать годовой объем продаж на основе размера нового магазина?
Как правило, для предсказания значений переменной используется регрессионный анализ. Его цель - разработать статистическую модель, позволяющую предсказывать значения зависимой переменной, или отклика, по значениям, по крайней мере одной, независимой, или объясняющей, переменной. В настоящей заметке мы рассмотрим простую линейную регрессию - статистический метод, позволяющий предсказывать значения зависимой переменной Y по значениям независимой переменной X . В последующих заметках будет описана модель множественной регрессии, предназначенная для предсказания значений независимой переменной Y по значениям нескольких зависимых переменных (Х 1 , Х 2 , …, X k ).
Скачать заметку в формате или , примеры в формате
Виды регрессионных моделей
где ρ 1 – коэффициент автокорреляции; если ρ 1 = 0 (нет автокорреляции), D ≈ 2; если ρ 1 ≈ 1 (положительная автокорреляции), D ≈ 0; если ρ 1 = -1 (отрицательная автокорреляции), D ≈ 4.
На практике применение критерия Дурбина-Уотсона основано на сравнении величины D с критическими теоретическими значениями d L и d U для заданного числа наблюдений n , числа независимых переменных модели k (для простой линейной регрессии k = 1) и уровня значимости α. Если D < d L , гипотеза о независимости случайных отклонений отвергается (следовательно, присутствует положительная автокорреляция); если D > d U , гипотеза не отвергается (то есть автокорреляция отсутствует); если d L < D < d U , нет достаточных оснований для принятия решения. Когда расчётное значение D превышает 2, то с d L и d U сравнивается не сам коэффициент D , а выражение (4 – D ).
Для вычисления статистики Дурбина-Уотсона в Excel обратимся к нижней таблице на рис. 14 Вывод остатка . Числитель в выражении (10) вычисляется с помощью функции =СУММКВРАЗН(массив1;массив2), а знаменатель =СУММКВ(массив) (рис. 16).

Рис. 16. Формулы расчета статистики Дурбина-Уотсона
В нашем примере D = 0,883. Основной вопрос заключается в следующем - какое значение статистики Дурбина-Уотсона следует считать достаточно малым, чтобы сделать вывод о существовании положительной автокорреляции? Необходимо соотнести значение D с критическими значениями (d L и d U ), зависящими от числа наблюдений n и уровня значимости α (рис. 17).

Рис. 17. Критические значения статистики Дурбина-Уотсона (фрагмент таблицы)
Таким образом, в задаче об объеме продаж в магазине, доставляющем товары на дом, существуют одна независимая переменная (k = 1), 15 наблюдений (n = 15) и уровень значимости α = 0,05. Следовательно, d L = 1,08 и d U = 1,36. Поскольку D = 0,883 < d L = 1,08, между остатками существует положительная автокорреляция, метод наименьших квадратов применять нельзя.
Проверка гипотез о наклоне и коэффициенте корреляции
Выше регрессия применялась исключительно для прогнозирования. Для определения коэффициентов регрессии и предсказания значения переменной Y при заданной величине переменной X использовался метод наименьших квадратов. Кроме того, мы рассмотрели среднеквадратичную ошибку оценки и коэффициент смешанной корреляции. Если анализ остатков подтверждает, что условия применимости метода наименьших квадратов не нарушаются, и модель простой линейной регрессии является адекватной, на основе выборочных данных можно утверждать, что между переменными в генеральной совокупности существует линейная зависимость.
Применение t -критерия для наклона. Проверяя, равен ли наклон генеральной совокупности β 1 нулю, можно определить, существует ли статистически значимая зависимость между переменными X и Y . Если эта гипотеза отклоняется, можно утверждать, что между переменными X и Y существует линейная зависимость. Нулевая и альтернативная гипотезы формулируются следующим образом: Н 0: β 1 = 0 (нет линейной зависимости), Н1: β 1 ≠ 0 (есть линейная зависимость). По определению t -статистика равна разности между выборочным наклоном и гипотетическим значением наклона генеральной совокупности, деленной на среднеквадратичную ошибку оценки наклона:
(11) t = (b 1 – β 1 ) / S b 1
где b
1
– наклон прямой регрессии по выборочным данным, β1 – гипотетический наклон прямой генеральной совокупности, ![]() , а тестовая статистика t
имеет t
-распределение с n – 2
степенями свободы.
, а тестовая статистика t
имеет t
-распределение с n – 2
степенями свободы.
Проверим, существует ли статистически значимая зависимость между размером магазина и годовым объемом продаж при α = 0,05. t -критерий выводится наряду с другими параметрами при использовании Пакета анализа (опция Регрессия ). Полностью результаты работы Пакета анализа приведены на рис. 4, фрагмент, относящийся к t-статистике – на рис. 18.
Рис. 18. Результаты применения t
Поскольку число магазинов n = 14 (см. рис.3), критическое значение t -статистики при уровне значимости α = 0,05 можно найти по формуле: t L =СТЬЮДЕНТ.ОБР(0,025;12) = –2,1788, где 0,025 – половина уровня значимости, а 12 = n – 2; t U =СТЬЮДЕНТ.ОБР(0,975;12) = +2,1788.
Поскольку t -статистика = 10,64 > t U = 2,1788 (рис. 19), нулевая гипотеза Н 0 отклоняется. С другой стороны, р -значение для Х = 10,6411, вычисляемое по формуле =1-СТЬЮДЕНТ.РАСП(D3;12;ИСТИНА), приближенно равно нулю, поэтому гипотеза Н 0 снова отклоняется. Тот факт, что р -значение почти равно нулю, означает, что если бы между размерами магазинов и годовым объемом продаж не существовало реальной линейной зависимости, обнаружить ее с помощью линейной регрессии было бы практически невозможно. Следовательно, между средним годовым объемом продаж в магазинах и их размером существует статистически значимая линейная зависимость.

Рис. 19. Проверка гипотезы о наклоне генеральной совокупности при уровне значимости, равном 0,05, и 12 степенях свободы
Применение F -критерия для наклона. Альтернативным подходом к проверке гипотез о наклоне простой линейной регрессии является использование F -критерия. Напомним, что F -критерий применяется для проверки отношения между двумя дисперсиями (подробнее см. ). При проверке гипотезы о наклоне мерой случайных ошибок является дисперсия ошибки (сумма квадратов ошибок, деленная на количество степеней свободы), поэтому F -критерий использует отношение дисперсии, объясняемой регрессией (т.е. величины SSR , деленной на количество независимых переменных k ), к дисперсии ошибок (MSE = S Y X 2 ).
По определению F -статистика равна среднему квадрату отклонений, обусловленных регрессией (MSR), деленному на дисперсию ошибки (MSE): F = MSR / MSE , где MSR = SSR / k , MSE = SSE /(n – k – 1), k – количество независимых переменных в регрессионной модели. Тестовая статистика F имеет F -распределение с k и n – k – 1 степенями свободы.
При заданном уровне значимости α решающее правило формулируется так: если F > F U , нулевая гипотеза отклоняется; в противном случае она не отклоняется. Результаты, оформленные в виде сводной таблицы дисперсионного анализа, приведены на рис. 20.

Рис. 20. Таблица дисперсионного анализа для проверки гипотезы о статистической значимости коэффициента регрессии
Аналогично t -критерию F -критерий выводится в таблицу при использовании Пакета анализа (опция Регрессия ). Полностью результаты работы Пакета анализа приведены на рис. 4, фрагмент, относящийся к F -статистике – на рис. 21.

Рис. 21. Результаты применения F -критерия, полученные с помощью Пакета анализа Excel
F-статистика равна 113,23, а р -значение близко к нулю (ячейка Значимость F ). Если уровень значимости α равен 0,05, определить критическое значение F -распределения с одной и 12 степенями свободы можно по формуле F U =F.ОБР(1-0,05;1;12) = 4,7472 (рис. 22). Поскольку F = 113,23 > F U = 4,7472, причем р -значение близко к 0 < 0,05, нулевая гипотеза Н 0 отклоняется, т.е. размер магазина тесно связан с его годовым объемом продаж.

Рис. 22. Проверка гипотезы о наклоне генеральной совокупности при уровне значимости, равном 0,05, с одной и 12 степенями свободы
Доверительный интервал, содержащий наклон β 1 . Для проверки гипотезы о существовании линейной зависимости между переменными можно построить доверительный интервал, содержащий наклон β 1 и убедиться, что гипотетическое значение β 1 = 0 принадлежит этому интервалу. Центром доверительного интервала, содержащего наклон β 1 , является выборочный наклон b 1 , а его границами - величины b 1 ± t n –2 S b 1
Как показано на рис. 18, b 1 = +1,670, n = 14, S b 1 = 0,157. t 12 =СТЬЮДЕНТ.ОБР(0,975;12) = 2,1788. Следовательно, b 1 ± t n –2 S b 1 = +1,670 ± 2,1788 * 0,157 = +1,670 ± 0,342, или + 1,328 ≤ β 1 ≤ +2,012. Таким образом, наклон генеральной совокупности с вероятностью 0,95 лежит в интервале от +1,328 до +2,012 (т.е. от 1 328 000 до 2 012 000 долл.). Поскольку эти величины больше нуля, между годовым объемом продаж и площадью магазина существует статистически значимая линейная зависимость. Если бы доверительный интервал содержал нуль, между переменными не было бы зависимости. Кроме того, доверительный интервал означает, что каждое увеличение площади магазина на 1 000 кв. футов приводит к увеличению среднего объема продаж на величину от 1 328 000 до 2 012 000 долларов.
Использование t -критерия для коэффициента корреляции. был введен коэффициент корреляции r , представляющий собой меру зависимости между двумя числовыми переменными. С его помощью можно установить, существует ли между двумя переменными статистически значимая связь. Обозначим коэффициент корреляции между генеральными совокупностями обеих переменных символом ρ. Нулевая и альтернативная гипотезы формулируются следующим образом: Н 0 : ρ = 0 (нет корреляции), Н 1 : ρ ≠ 0 (есть корреляция). Проверка существования корреляции:

где r = + , если b 1 > 0, r = – , если b 1 < 0. Тестовая статистика t имеет t -распределение с n – 2 степенями свободы.
В задаче о сети магазинов Sunflowers r 2 = 0,904, а b 1 - +1,670 (см. рис. 4). Поскольку b 1 > 0, коэффициент корреляции между объемом годовых продаж и размером магазина равен r = +√0,904 = +0,951. Проверим нулевую гипотезу, утверждающую, что между этими переменными нет корреляции, используя t -статистику:

При уровне значимости α = 0,05 нулевую гипотезу следует отклонить, поскольку t = 10,64 > 2,1788. Таким образом, можно утверждать, что между объемом годовых продаж и размером магазина существует статистически значимая связь.
При обсуждении выводов, касающихся наклона генеральной совокупности, доверительные интервалы и критерии для проверки гипотез являются взаимозаменяемыми инструментами. Однако вычисление доверительного интервала, содержащего коэффициент корреляции, оказывается более сложным делом, поскольку вид выборочного распределения статистики r зависит от истинного коэффициента корреляции.
Оценка математического ожидания и предсказание индивидуальных значений
В этом разделе рассматриваются методы оценки математического ожидания отклика Y и предсказания индивидуальных значений Y при заданных значениях переменной X .
Построение доверительного интервала. В примере 2 (см. выше раздел Метод наименьших квадратов ) регрессионное уравнение позволило предсказать значение переменной Y X . В задаче о выборе места для торговой точки средний годовой объем продаж в магазине площадью 4000 кв. футов был равен 7,644 млн. долл. Однако эта оценка математического ожидания генеральной совокупности является точечной. для оценки математического ожидания генеральной совокупности была предложена концепция доверительного интервала. Аналогично можно ввести понятие доверительного интервала для математического ожидания отклика при заданном значении переменной X :
где  , =
b
0
+
b
1
X i
– предсказанное значение переменное Y
при X
= X i
, S YX
– среднеквадратичная ошибка, n
– объем выборки, X
i
- заданное значение переменной X
, µ
Y
| X
=
X
i
– математическое ожидание переменной Y
при Х
= Х i
, SSX =
, =
b
0
+
b
1
X i
– предсказанное значение переменное Y
при X
= X i
, S YX
– среднеквадратичная ошибка, n
– объем выборки, X
i
- заданное значение переменной X
, µ
Y
| X
=
X
i
– математическое ожидание переменной Y
при Х
= Х i
, SSX = 
Анализ формулы (13) показывает, что ширина доверительного интервала зависит от нескольких факторов. При заданном уровне значимости возрастание амплитуды колебаний вокруг линии регрессии, измеренное с помощью среднеквадратичной ошибки, приводит к увеличению ширины интервала. С другой стороны, как и следовало ожидать, увеличение объема выборки сопровождается сужением интервала. Кроме того, ширина интервала изменяется в зависимости от значений X i . Если значение переменной Y предсказывается для величин X , близких к среднему значению , доверительный интервал оказывается уже, чем при прогнозировании отклика для значений, далеких от среднего.
Допустим, что, выбирая место для магазина, мы хотим построить 95%-ный доверительный интервал для среднего годового объема продаж во всех магазинах, площадь которых равна 4000 кв. футов:

Следовательно, средний годовой объем продаж во всех магазинах, площадь которых равна 4 000 кв. футов, с 95% -ной вероятностью лежит в интервале от 6,971 до 8,317 млн. долл.
Вычисление доверительного интервала для предсказанного значения. Кроме доверительного интервала для математического ожидания отклика при заданном значении переменной X , часто необходимо знать доверительный интервал для предсказанного значения. Несмотря на то что формула для вычисления такого доверительного интервала очень похожа на формулу (13), этот интервал содержит предсказанное значение, а не оценку параметра. Интервал для предсказанного отклика Y X = Xi при конкретном значении переменной X i определяется по формуле:

Предположим, что, выбирая место для торговой точки, мы хотим построить 95%-ный доверительный интервал для предсказанного годового объема продаж в магазине, площадь которого равна 4000 кв. футов:

Следовательно, предсказанный годовой объем продаж в магазине, площадь которого равна 4000 кв. футов, с 95%-ной вероятностью лежит в интервале от 5,433 до 9,854 млн. долл. Как видим, доверительный интервал для предсказанного значения отклика намного шире, чем доверительный интервал для его математического ожидания. Это объясняется тем, что изменчивость при прогнозировании индивидуальных значений намного больше, чем при оценке математического ожидания.
Подводные камни и этические проблемы, связанные с применением регрессии
Трудности, связанные с регрессионным анализом:
- Игнорирование условий применимости метода наименьших квадратов.
- Ошибочная оценка условий применимости метода наименьших квадратов.
- Неправильный выбор альтернативных методов при нарушении условий применимости метода наименьших квадратов.
- Применение регрессионного анализа без глубоких знаний о предмете исследования.
- Экстраполяция регрессии за пределы диапазона изменения объясняющей переменной.
- Путаница между статистической и причинно-следственной зависимостями.
Широкое распространение электронных таблиц и программного обеспечения для статистических расчетов ликвидировало вычислительные проблемы, препятствовавшие применению регрессионного анализа. Однако это привело к тому, что регрессионный анализ стали применять пользователи, не обладающие достаточной квалификацией и знаниями. Откуда пользователям знать об альтернативных методах, если многие из них вообще не имеют ни малейшего понятия об условиях применимости метода наименьших квадратов и не умеют проверять их выполнение?
Исследователь не должен увлекаться перемалыванием чисел - вычислением сдвига, наклона и коэффициента смешанной корреляции. Ему нужны более глубокие знания. Проиллюстрируем это классическим примером, взятым из учебников. Анскомб показал, что все четыре набора данных, приведенных на рис. 23, имеют одни и те же параметры регрессии (рис. 24).

Рис. 23. Четыре набора искусственных данных

Рис. 24. Регрессионный анализ четырех искусственных наборов данных; выполнен с помощью Пакета анализа (кликните на рисунке, чтобы увеличить изображение)
Итак, с точки зрения регрессионного анализа все эти наборы данных совершенно идентичны. Если бы анализ был на этом закончен, мы потеряли бы много полезной информации. Об этом свидетельствуют диаграммы разброса (рис. 25) и графики остатков (рис. 26), построенные для этих наборов данных.

Рис. 25. Диаграммы разброса для четырех наборов данных
Диаграммы разброса и графики остатков свидетельствуют о том, что эти данные отличаются друг от друга. Единственный набор, распределенный вдоль прямой линии, - набор А. График остатков, вычисленных по набору А, не имеет никакой закономерности. Этого нельзя сказать о наборах Б, В и Г. График разброса, построенный по набору Б, демонстрирует ярко выраженную квадратичную модель. Этот вывод подтверждается графиком остатков, имеющим параболическую форму. Диаграмма разброса и график остатков показывают, что набор данных В содержит выброс. В этой ситуации необходимо исключить выброс из набора данных и повторить анализ. Метод, позволяющий обнаруживать и исключать выбросы из наблюдений, называется анализом влияния. После исключения выброса результат повторной оценки модели может оказаться совершенно иным. Диаграмма разброса, построенная по данным из набора Г, иллюстрирует необычную ситуацию, в которой эмпирическая модель значительно зависит от отдельного отклика (Х 8 = 19, Y 8 = 12,5). Такие регрессионные модели необходимо вычислять особенно тщательно. Итак, графики разброса и остатков являются крайне необходимым инструментом регрессионного анализа и должны быть его неотъемлемой частью. Без них регрессионный анализ не заслуживает доверия.

Рис. 26. Графики остатков для четырех наборов данных
Как избежать подводных камней при регрессионном анализе:
- Анализ возможной взаимосвязи между переменными X и Y всегда начинайте с построения диаграммы разброса.
- Прежде чем интерпретировать результаты регрессионного анализа, проверяйте условия его применимости.
- Постройте график зависимости остатков от независимой переменной. Это позволит определить, насколько эмпирическая модель соответствует результатам наблюдения, и обнаружить нарушение постоянства дисперсии.
- Для проверки предположения о нормальном распределении ошибок используйте гистограммы, диаграммы «ствол и листья», блочные диаграммы и графики нормального распределения.
- Если условия применимости метода наименьших квадратов не выполняются, используйте альтернативные методы (например, модели квадратичной или множественной регрессии).
- Если условия применимости метода наименьших квадратов выполняются, необходимо проверить гипотезу о статистической значимости коэффициентов регрессии и построить доверительные интервалы, содержащие математическое ожидание и предсказанное значение отклика.
- Избегайте предсказывать значения зависимой переменной за пределами диапазона изменения независимой переменной.
- Имейте в виду, что статистические зависимости не всегда являются причинно-следственными. Помните, что корреляция между переменными не означает наличия причинно-следственной зависимости между ними.
Резюме. Как показано на структурной схеме (рис. 27), в заметке описаны модель простой линейной регрессии, условия ее применимости и способы проверки этих условий. Рассмотрен t -критерий для проверки статистической значимости наклона регрессии. Для предсказания значений зависимой переменной использована регрессионная модель. Рассмотрен пример, связанный с выбором места для торговой точки, в котором исследуется зависимость годового объема продаж от площади магазина. Полученная информация позволяет точнее выбрать место для магазина и предсказать его годовой объем продаж. В следующих заметках будет продолжено обсуждение регрессионного анализа, а также рассмотрены модели множественной регрессии.

Рис. 27. Структурная схема заметки
Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 792–872
Если зависимая переменная является категорийной, необходимо применять логистическую регрессию.
Пакет MS Excel позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро. Важно понять, как интерпретировать полученные результаты. Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия (в Excel 2007 этот режим находится в блоке Данные/Анализ данных/Регрессия). Затем полученные результаты скопировать в блок для анализа.

Регрессия в программе Excel
Статистическая обработка данных может также проводиться с помощью надстройки Пакет анализа в подпункте меню «Сервис». В программе Excel 2003, если открыв СЕРВИС , не находим вкладку АНАЛИЗ ДАННЫХ , то щелчком левой кнопки мыши открываем вкладку НАДСТРОЙКИ и напротив пункта ПАКЕТ АНАЛИЗА щелчком левой кнопки мыши ставим галочку (рис. 17).
Рис. 17. Окно НАДСТРОЙКИ
После этого в меню СЕРВИС появляется вкладка АНАЛИЗ ДАННЫХ .
В Excel 2007 для установки ПАКЕТА АНАЛИЗА нужно нажать на кнопку OFFICE в левом верхнем углу листа (рис. 18а). Далее нажимаем на кнопку ПАРАМЕТРЫ EXCEL . В появившемся окне ПАРАМЕТРЫ EXCEL нажимаем левой кнопкой мыши на пункт НАДСТРОЙКИ и в правой части раскрывшегося списка выбираем пункт ПАКЕТ АНАЛИЗА. Далее нажимаем на ОК .




Рис. 18. Установка ПАКЕТА АНАЛИЗА в Excel 2007
Чтобы Пакет анализа был установлен, нажимаем на кнопку ПЕРЕЙТИ, расположенную внизу раскрытого окна. Появитсяокно, показанное на рис. 12.Ставим галочку напротив ПАКЕТА АНАЛИЗА. Во вкладке ДАННЫЕ появится кнопка АНАЛИЗ ДАННЫХ (рис. 19).

Из предложенных пунктов выбирает пункт «РЕГРЕССИЯ » и щелкаем на нем левой кнопкой мыши. Далее нажимаем ОК.

Появится окно, показанное на рис. 21

Инструмент анализа «РЕГРЕССИЯ » применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
Инструмент «Регрессия» использует функцию ЛИНЕЙН .
Диалоговое окно «РЕГРЕССИЯ»
Метки Установите флажок, если первая строка или первый столбец входного диапазона содержит заголовки. Снимите этот флажок, если заголовки отсутствуют. В этом случае подходящие заголовки для данных выходной таблицы будут созданы автоматически.
Уровень надежности Установите флажок, чтобы включить в выходную таблицу итогов дополнительный уровень. В соответствующее поле введите уровень надежности, который следует применить, дополнительно к уровню 95%, применяемому по умолчанию.
Константа - ноль Установите флажок, чтобы линия регрессии прошла через начало координат.
Выходной интервал Введите ссылку на левую верхнюю ячейку выходного диапазона. Отведите как минимум семь столбцов для выходной таблицы итогов, которая будет включать в себя: результаты дисперсионного анализа, коэффициенты, стандартную погрешность вычисления Y, среднеквадратичные отклонения, число наблюдений, стандартные погрешности для коэффициентов.
Новый рабочий лист Установите переключатель в это положение, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. При необходимости введите имя для нового листа в поле, расположенном напротив соответствующего положения переключателя.
Новая рабочая книга Установите переключатель в это положение для создания новой книги, в которой результаты будут добавлены в новый лист.
Остатки Установите флажок для включения остатков в выходную таблицу.
Стандартизированные остатки Установите флажок для включения стандартизированных остатков в выходную таблицу.
График остатков Установите флажок для построения графика остатков для каждой независимой переменной.
График подбора Установите флажок для построения графика зависимости предсказанных значений от наблюдаемых.
График нормальной вероятности Установите флажок, для построения графика нормальной вероятности.
Функция ЛИНЕЙН
Для проведения расчетов выделяем курсором ячейку, в которой хотим отобразить среднее значение и нажимаем на клавиатуре клавишу =. Далее в поле Имя указываем нужную функцию, например СРЗНАЧ (рис. 22).

Рис. 22 Поиск функций в программе Excel 2003
Если в поле ИМЯ название функции не появилось, то левой кнопкой мыши щелкаем на треугольник рядом с полем, после этого появится окно со списком функций. Если данной функции в списке нет, то левой кнопкой мыши нажимаем на пункт списка ДРУГИЕ ФУНКЦИИ , появится диалоговое окно МАСТЕР ФУНКЦИЙ , в котором с помощью вертикальной прокрутки выбираем нужную функцию, выделяем ее курсором и нажимаем на ОК (рис. 23).

Рис. 23. Мастер функций
Для поиска функции в программе Excel 2007 в меню может быть открыта любая вкладка, тогда для проведения расчетов выделяем курсором ячейку, в которой хотим отобразить среднее значение и нажимаем на клавиатуре клавишу =. Далее в поле Имя указываем функцию СРЗНАЧ . Окно для расчета функции аналогично приведенному в Excel 2003.
Также можно выбрать вкладку Формулы и нажать левой кнопкой мыши на кнопку в меню «ВСТАВИТЬ ФУНКЦИЮ » (рис. 24), появится окно МАСТЕР ФУНКЦИЙ , вид которого аналогичен Excel 2003. Также в меню можно сразу выбрать категорию функций (недавно использовались, финансовые, логические, текстовые, дата и время, математические, другие функции), в которой будем искать нужную функцию.




Рис. 24 Выбор функции в Excel 2007
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Можно также объединять функцию ЛИНЕЙН с другими функциями для вычисления других видов моделей, являющихся линейными в неизвестных параметрах (неизвестные параметры которых являются линейными), включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива.
Уравнение для прямой линии имеет следующий вид:
(в случае нескольких диапазонов значений x),
где зависимое значение y - функция независимого значения x, значения m - коэффициенты, соответствующие каждой независимой переменной x, а b - постоянная. Обратите внимание, что y, x и m могут быть векторами. Функция ЛИНЕЙН
возвращает массив ![]() . ЛИНЕЙН
может также возвращать дополнительную регрессионную статистику.
. ЛИНЕЙН
может также возвращать дополнительную регрессионную статистику.
ЛИНЕЙН (известные_значения_y; известные_значения_x; конст; статистика)
Известные_значения_y - множество значений y, которые уже известны для соотношения .
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
Известные_значения_x - необязательное множество значений x, которые уже известны для соотношения .
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы_известные_значения_y и известные_значения_x могут иметь любую форму - при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
Если массив_известные_значения_x опущен, то предполагается, что этот массив {1;2;3;...} имеет такой же размер, как и массив_известные_значения_y.
Конст - логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
Если аргумент «конст» имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
Если аргумент «конст» имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение .
Статистика - логическое значение, которое указывает, требуется ли вернуть дополнительную статистику по регрессии.
Если аргумент «статистика» имеет значение ИСТИНА, функция ЛИНЕЙН возвращает дополнительную регрессионную статистику. Возвращаемый массив будет иметь следующий вид: {mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid}.
Если аргумент «статистика» имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
Дополнительная регрессионная статистика.
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика.

Замечания:
Любую прямую можно описать ее наклоном и пересечением с осью y:
Наклон (m): чтобы определить наклон прямой, обычно обозначаемый через m, нужно взять две точки прямой и ; наклон будет равен ![]() .
.
Y-пересечение (b): Y-пересечением прямой, обычно обозначаемым через b, является значение y для точки, в которой прямая пересекает ось y.
Уравнение прямой имеет вид . Если известны значения m и b, то можно вычислить любую точку на прямой, подставляя значения y или x в уравнение. Можно также воспользоваться функцией ТЕНДЕНЦИЯ.
Если имеется только одна независимая переменная x, можно получить наклон и y-пересечение непосредственно, воспользовавшись следующими формулами:
Наклон: ИНДЕКС (ЛИНЕЙН(известные_значения_y; известные_значения_x); 1)
Y-пересечение: ИНДЕКС (ЛИНЕЙН (известные_значения_y; известные_значения_x); 2)
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точной является модель, используемая функцией ЛИНЕЙН. Функция ЛИНЕЙН использует метод наименьших квадратов для определения наилучшей аппроксимации данных. Когда имеется только одна независимая переменная x, m и b вычисляются по следующим формулам:

где x и y – выборочные средние значения, например x = СРЗНАЧ (известные_значения_x), а y = СРЗНАЧ (известные_значения_y).
Функции аппроксимации ЛИНЕЙН и ЛГРФПРИБЛ могут вычислить прямую или экспоненциальную кривую, наилучшим образом описывающую данные. Однако они не дают ответа на вопрос, какой из двух результатов больше подходит для решения поставленной задачи. Можно также вычислить функцию ТЕНДЕНЦИЯ (известные_значения_y; известные_значения_x) для прямой или функцию РОСТ(известные_значения_y; известные_значения_x) для экспоненциальной кривой. Эти функции, если не задавать аргумент новые_значения_x, возвращают массив вычисленных значений y для фактических значений x в соответствии с прямой или кривой. После этого можно сравнить вычисленные значения с фактическими значениями. Можно также построить диаграммы для визуального сравнения.
Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат разности между прогнозируемым значением y и фактическим значением y. Сумма этих квадратов разностей называется остаточной суммой квадратов (ssresid). Затем Microsoft Excel подсчитывает общую сумму квадратов (sstotal). Если конст = ИСТИНА или значение этого аргумента не указано, общая сумма квадратов будет равна сумме квадратов разностей действительных значений y и средних значений y. При конст = ЛОЖЬ общая сумма квадратов будет равна сумме квадратов действительных значений y (без вычитания среднего значения y из частного значения y). После этого регрессионную сумму квадратов можно вычислить следующим образом: ssreg = sstotal - ssresid. Чем меньше остаточная сумма квадратов, тем больше значение коэффициента детерминированности r2, который показывает, насколько хорошо уравнение, полученное с помощью регрессионного анализа, объясняет взаимосвязи между переменными. Коэффициент r2 равен ssreg/sstotal.
В некоторых случаях один или более столбцов X (пусть значения Y и X находятся в столбцах) не имеет дополнительного предикативного значения в других столбцах X. Другими словами, удаление одного или более столбцов X может привести к значениям Y, вычисленным с одинаковой точностью. В этом случае избыточные столбцы X будут исключены из модели регрессии. Этот феномен называется «коллинеарностью», поскольку избыточные столбцы X могут быть представлены в виде суммы нескольких неизбыточных столбцов. Функция ЛИНЕЙН проверяет на коллинеарность и удаляет из модели регрессии все избыточные столбцы X, если обнаруживает их. Удаленные столбцы X можно определить в выходных данных ЛИНЕЙН по коэффициенту, равному 0, и по значению se, равному 0. Удаление одного или более столбцов как избыточных изменяет величину df, поскольку она зависит от количества столбцов X, в действительности используемых для предикативных целей. Подробнее о вычислении величины df см. ниже в примере 4. При изменении df вследствие удаления избыточных столбцов значения sey и F также изменяются. Часто использовать коллинеарность не рекомендуется. Однако ее следует применять, если некоторые столбцы X содержат 0 или 1 в качестве индикатора указывающего, входит ли предмет эксперимента в отдельную группу. Если конст = ИСТИНА или значение этого аргумента не указано, функция ЛИНЕЙН вставляет дополнительный столбец X для моделирования точки пересечения. Если имеется столбец со значениями 1 для указания мужчин и 0 - для женщин, а также имеется столбец со значениями 1 для указания женщин и 0 - для мужчин, то последний столбец удаляется, поскольку его значения можно получить из столбца с «индикатором мужского пола».
Вычисление df для случаев, когда столбцы X не удаляются из модели вследствие коллинеарности происходит следующим образом: если существует k столбцов известных_значений_x и значение конст = ИСТИНА или не указано, то df = n – k – 1. Если конст = ЛОЖЬ, то df = n - k. В обоих случаях удаление столбцов X вследствие коллинеарности увеличивает значение df на 1.
Формулы, которые возвращают массивы, должны быть введены как формулы массива.
При вводе массива констант в качестве, например, аргумента известные_значения_x следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть различными в зависимости от параметров, заданных в окне «Язык и стандарты» на панели управления.
Следует отметить, что значения y, предсказанные с помощью уравнения регрессии, возможно, не будут правильными, если они располагаются вне интервала значений y, которые использовались для определения уравнения.
Основной алгоритм, используемый в функции ЛИНЕЙН , отличается от основного алгоритма функций НАКЛОН и ОТРЕЗОК . Разница между алгоритмами может привести к различным результатам при неопределенных и коллинеарных данных. Например, если точки данных аргумента известные_значения_y равны 0, а точки данных аргумента известные_значения_x равны 1, то:
Функция ЛИНЕЙН возвращает значение, равное 0. Алгоритм функции ЛИНЕЙН используется для возвращения подходящих значений для коллинеарных данных, и в данном случае может быть найден по меньшей мере один ответ.
Функции НАКЛОН и ОТРЕЗОК возвращают ошибку #ДЕЛ/0!. Алгоритм функций НАКЛОН и ОТРЕЗОК используется для поиска только одного ответа, а в данном случае их может быть несколько.
Помимо вычисления статистики для других типов регрессии функцию ЛИНЕЙН можно использовать при вычислении диапазонов для других типов регрессии, вводя функции переменных x и y как ряды переменных х и у для ЛИНЕЙН. Например, следующая формула:
ЛИНЕЙН(значения_y, значения_x^СТОЛБЕЦ($A:$C))
работает при наличии одного столбца значений Y и одного столбца значений Х для вычисления аппроксимации куба (многочлен 3-й степени) следующей формы:
Формула может быть изменена для расчетов других типов регрессии, но в отдельных случаях требуется корректировка выходных значений и других статистических данных.